第 2 章 Harness 解剖学:model + harness 与 Codex 全景架构¶
上一章我们说清了"火的是模型外面那层"。这一章,我们把那层东西摊开在解剖台上:先给出贯穿全书的同心层心智模型,再打开 Codex 的源码仓库,看这套抽象怎么落成一个有一百多个 crate 的真实工程,最后教你怎么读它才不会迷路。
本章是全书的"地图章"。读完它,你手里会有两样东西:一张概念地图(harness 的分层),和一张代码地图(每层落在 Codex 哪个目录)。后面 15 章,都是在这两张图上逐格放大。
引子:clone 下来,然后被一屏目录劝退¶
假设你听了上一章,决定亲手读读 Codex。你把仓库 clone 下来,进到 Rust 实现的根目录 codex-rs/,敲一个 tree -L 1,想先看看它长什么样——
然后你愣住了。屏幕哗啦啦刷出一整屏(这里截一段):
codex-rs
├── agent-graph-store
├── agent-identity
├── analytics
├── app-server
├── app-server-client
├── app-server-daemon
├── app-server-protocol
├── apply-patch
├── cli
├── code-mode
├── codex-mcp
├── config
├── connectors
├── core
├── core-skills
├── exec
├── execpolicy
├── ext/ # goal / guardian / memories / web-search / image-generation
├── linux-sandbox
├── mcp-server
├── memories/ # read / write
├── otel
├── sandboxing
├── skills
├── tools
├── tui
├── utils/ # 还塞着二十多个小 crate
├── windows-sandbox-rs
├── Cargo.toml
└── … # 省略五十多个;光 workspace 成员就有 116 个 crate
这是大多数人读大型开源项目的第一道坎:不是看不懂某一段代码,而是不知道从哪看起。 你随手点开 core,里面又是几十个 .rs 文件;你点开 app-server,发现它还分了 protocol、client、daemon、transport 四个兄弟 crate。读了半小时,你对"Codex 是怎么工作的"还是没有任何整体感。
这一章就是来解决这道坎的。我们不从任何一个文件读起——我们先画地图。
一、agent = model + harness:把抽象拆成同心层¶
先把上一章那句话变成一张图。
LangChain 有个干脆的拆法:一个 agent = 一个模型 + 一套 harness。 模型负责"想",harness 负责把"想"变成"在真实世界里可靠地做"。这本书的全部内容,都是在拆右边那个 harness。
但"harness"是个筐,什么都能往里装。为了能一层层讲、一层层读,我们给它一个结构——把它想象成一圈圈包在模型外面的同心层,由内到外:

图 1:Agent = 模型 + Harness 的同心层,本章作为全书地图全亮展示。
为什么是"同心层",而不是并列的几个框?因为它们之间有依赖与包裹关系:
- 最内核是 模型。它是这套系统里唯一你不拥有、直接买来用的部件。harness engineering 不碰它——我们改的全是它外面的东西。
- 紧贴着模型的是 循环(Loop):把"调模型 → 看它要调什么工具 → 执行 → 把结果喂回去 → 再调模型"转起来。没有循环,模型只能一问一答,做不成多步任务。
- 再外面是 上下文(Context):每一轮到底把什么塞进模型的输入窗口——系统提示、仓库知识、历史、当前环境。它决定模型"看得见什么"。
- 然后是 工具(Tools):模型的手。读写文件、跑命令、改代码。
- 工具外面是 能力(Skills & MCP):把成套的专家流程(skill)和外部工具(MCP)可插拔地接进来,且不撑爆上下文。
- 再外面是 约束与安全(Guardrails):执行策略、沙箱、审批、守护——让模型"放手干"又不闯祸。
- 然后是 长程状态(Long-running):压缩、目标、记忆,让任务能跨越多个上下文窗口"换班"接力。
- 接着是 多代理(Multi-agent):一个 agent 不够时,派生、协调、共享状态。
- 再外面是 评估与观测(Eval & Observability):谁来判断"做对了",以及怎么让运行时信号对 agent 可见。
- 最外层是 运行时(Runtime):这套 harness 怎么被你的 IDE、命令行、甚至另一个 agent 调用。
记住这张图的形状就行:一个模型,被一圈圈挽具包着,越往外越"工程",越往里越"智能"。本书第 3 到 14 章,就是从里到外,一层一层拆。第 15 章再把它们装回去,讲怎么造你自己的整套。
二、打开 codex-rs:一个有 116 个 crate 的 workspace¶
现在把概念地图放一边,打开真实的代码。
codex-rs/ 是一个 Rust 的 Cargo workspace——一个仓库里管着一大堆相互依赖的 crate(你可以粗略理解成"模块/包")。打开根目录的 Cargo.toml,[workspace].members 下面老老实实列着 116 个成员。这个数字本身,就是这一章第一个值得停下来想的现象。
为什么要拆成 116 个 crate?¶
一个很自然的疑问:一个命令行工具,至于拆这么碎吗?
答案藏在 Codex 自己的 AGENTS.md 里。那份给 agent 看的开发说明,有一条态度强硬的纪律,原话大意是:
"抵制往
codex-core里加代码!"(resist adding code to codex-core)
它解释说:core 是最大的 crate,正因为大,大家就图省事往里塞,于是它越来越臃肿。所以团队立了规矩——加新功能前,先问自己:能不能放进别的 crate?是不是该新开一个 crate?审查代码时,也要主动挡回那些"无谓地把代码堆进 core"的改动。
把这条纪律和上一章 OpenAI 那篇文章对上,你会心一笑:他们反复强调,agent 在有强边界、结构可预测的环境里干得最好;所以他们围绕应用立了一套刚性的架构模型,用自定义 linter 和结构化测试机械地强制这些边界。116 个 crate,不是过度设计,而是把"边界"这件事焊死在工程结构里——每个 crate 就是一道边界,依赖关系清清楚楚,agent(和人)都不容易越界乱来。
这也给你递了本书的一条暗线:好的 harness,往往先是好的架构。 后面讲约束(第 9 章)和工程实践(第 15 章)时,我们会一次次回到这个主题。
顺便看一眼这个 workspace 的
[workspace.lints.clippy]:unwrap_used = "deny"、expect_used = "deny"、uninlined_format_args = "deny"……几十条 lint 被设成"deny"(违反就报错、过不了)。这些就是 OpenAI 文章里说的"taste invariants(品味不变量)"——把人的工程审美,一次性编码成机器每次都强制执行的规则。第 4 章和第 15 章我们会专门讲它。
按层导览:116 个 crate 大致怎么归类¶
你当然不用记住 116 个名字。我们按上一节那张同心层图,把关键 crate 归归类,你只要建立"哪一层大概住在哪几个 crate"的直觉就够了:
- 核心引擎 / 循环:
core(codex-core,最大的 crate,业务逻辑的心脏)、core-api、protocol、codex-client、state、thread-store、rollout(会话回放/记录)。 - 上下文:主要在
core内部(core/src/context/、core/src/context_manager/),加上collaboration-mode-templates(plan / execute / pair_programming / default 几种协作模式的模板)。 - 工具:
tools(codex-tools)、apply-patch(改代码的补丁工具)、code-mode+v8-poc(让模型"写代码调用工具"的实验性运行时)、shell-command、shell-escalation。 - 能力:Skills 与 MCP:
skills+core-skills(技能引擎)、codex-mcp+mcp-server+rmcp-client(MCP 客户端/服务端)、connectors、plugin+core-plugins、以及ext/web-search、ext/image-generation这些"扩展"。 - 约束与安全:
execpolicy+execpolicy-legacy(执行策略)、linux-sandbox+bwrap、windows-sandbox-rs、sandboxing(跨平台沙箱)、ext/guardian(codex-guardian,独立的"复核者")、network-proxy、process-hardening、secrets+keyring-store。 - 长程状态:
ext/goal(目标)、ext/memories+memories/read+memories/write(记忆的读写),加上core内部的压缩(compact*)。 - 多代理:
agent-graph-store(多代理共享的状态图)、agent-identity、external-agent-sessions、external-agent-migration。 - 评估与观测:
analytics(遥测)、otel(OpenTelemetry 接入)、feedback、response-debug-context。 - 运行时 & 协议:
app-server一家四口(app-server/-protocol/-client/-daemon,外加-transport、-test-client)、exec+exec-server(headless)、cli、tui、uds/stdio-to-uds(进程间通信)。 - 模型接入:
model-provider+model-provider-info+models-manager、ollama、lmstudio、chatgpt、backend-client、login、responses-api-proxy、realtime-webrtc。 - 一大堆基础设施:
utils/(二十多个小 crate:absolute-path、pty、fuzzy-match、stream-parser、template……)、ansi-escape、file-search、file-watcher、git-utils、async-utils、arg0、terminal-detection等。
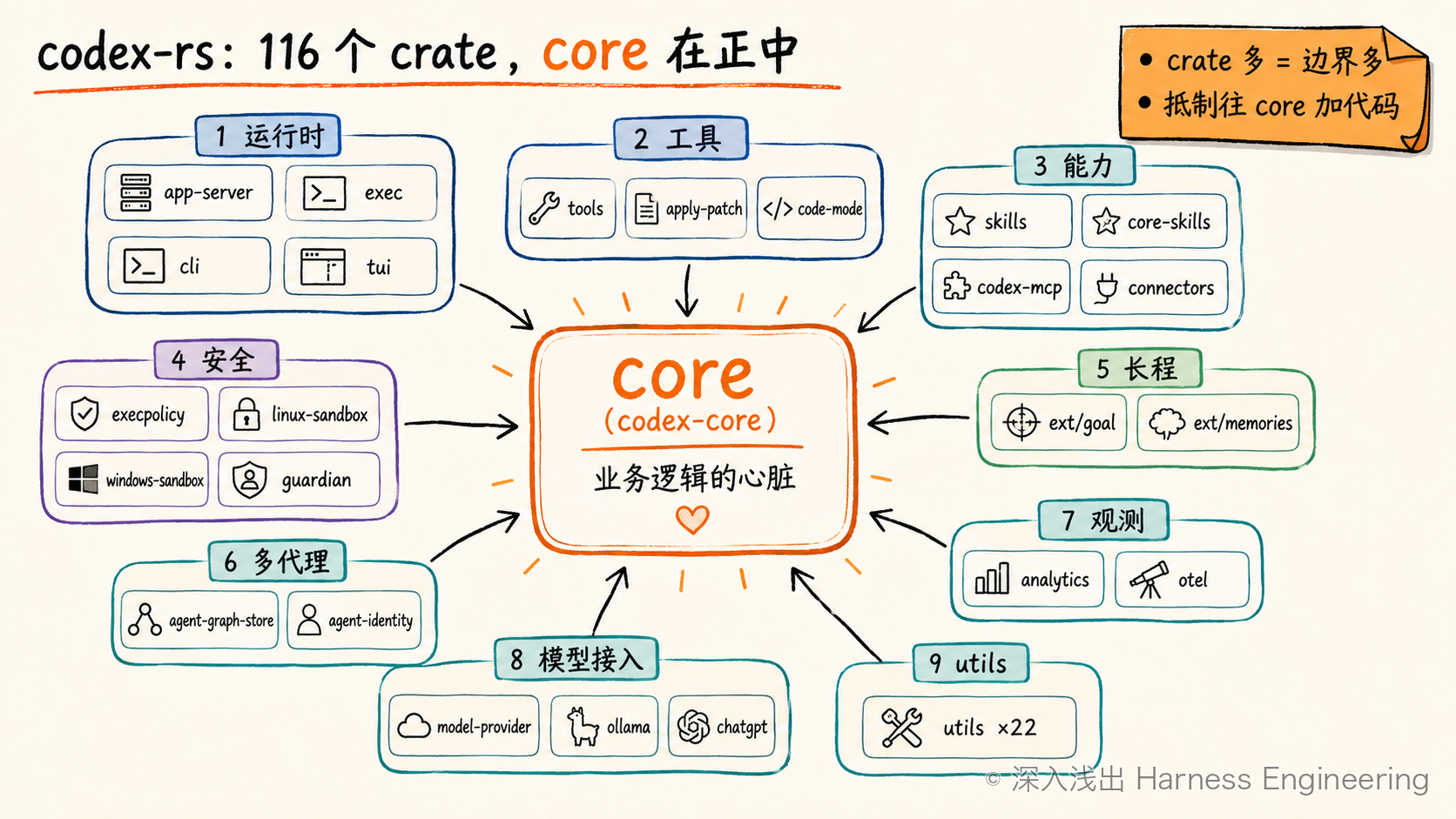
图 2:codex-rs 的 crate 边界,core 位于业务逻辑中心。
看出门道了吗?这张代码地图,几乎就是上一节那张概念地图的投影。 这正是我们选 Codex 当解剖标本的核心理由:你想理解 harness 的某一层,几乎总能在仓库里找到一两个名字直白、边界清晰的 crate 对应过去。
三、概念层 ↔ 代码目录:全书的总索引¶
把两张地图叠起来,就得到这本书的总索引。下面这张表,建议你折角,后面每一章我们都会回来对一次"我们在哪":
| 同心层 | 它解决的核心问题 | Codex 主要落点 | 本书章节 |
|---|---|---|---|
| 循环 Loop | 让模型能多步地"调工具→看结果→再决定" | core/src/session/、core/src/client.rs、tasks/ |
第 3 章 |
| 上下文 Context | 每轮喂什么给模型;地图而非手册 | core/src/context/、context_manager/、agents_md.rs、*_prompt.md |
第 4 章 |
| 工具 Tools | 模型的手;改代码本身如何工程化 | core/src/tools/、apply-patch、code-mode |
第 5–6 章 |
| 能力 Skills & MCP | 可插拔技能/外部工具;不撑爆上下文的加载 | skills + core-skills、codex-mcp + mcp-server、connectors |
第 7–8 章 |
| 约束·安全 Guardrails | 放手干又不闯祸 | execpolicy、linux-sandbox / windows-sandbox-rs / sandboxing、ext/guardian |
第 9 章 |
| 长程 Long-running | 跨上下文窗口"换班"接力 | core 内 compact*、ext/goal、ext/memories + memories/{read,write} |
第 10 章 |
| 多代理 Multi-agent | 一个不够时,派生/通信/共享状态 | core/src/agent/、agent-graph-store、agent-identity |
第 11 章 |
| 评估·观测 Eval & Obsv | 谁判断"做对了";让信号对 agent 可见 | core/src/session/review.rs、analytics、otel |
第 12–13 章 |
| 运行时 Runtime | harness 怎么被宿主调用 | app-server*、exec、cli、tui |
第 14 章 |
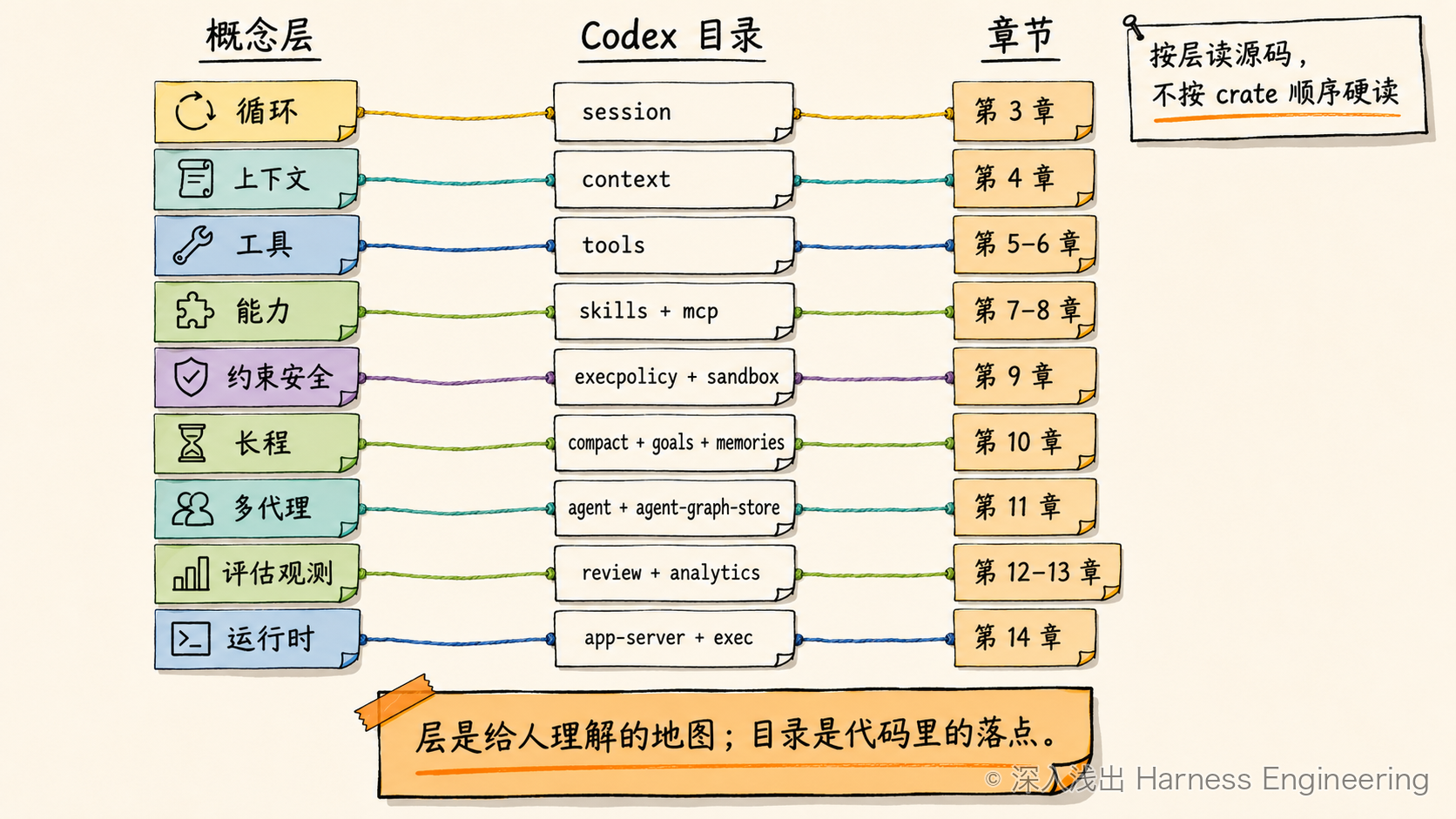
图 3:从 Harness 概念层映射到 Codex 的主要代码落点。
这张表也回答了一个你可能有的疑问:为什么不按 crate 顺序讲,而按"层"讲? 因为 crate 是给编译器和打包看的物理划分,"层"才是给人理解用的概念划分。同一层可能散在几个 crate(比如安全散在 execpolicy / linux-sandbox / guardian),同一个 crate 也可能横跨几层(core 几乎每层都沾)。本书永远以"层"为单位推进——每章锁定一层,只读那一层真正关键的三五个文件。
四、深入 core:一个 crate 内部的模块树¶
116 个 crate 里,core(codex-core)是当之无愧的心脏——尽管团队拼命往外搬,它仍然是最大、最关键的那个。我们打开它的入口文件 core/src/lib.rs,看它把自己分成了哪些模块。挑几个你已经眼熟的(注释是我加的):
pub(crate) mod session; // 循环:一次 turn 的生命周期(第 3 章)
mod client; // 模型客户端:把上下文打成请求、解析流式响应
mod client_common;
pub mod context; // 上下文:每轮喂什么(第 4 章)
mod context_manager; // 历史的规整与管理
mod compact_remote; // 压缩:长程作业的核心装备之一(第 10 章)
mod goals; // 目标:长期目标 / 预算 / 续作(第 10 章)
mod agent; // 多代理(第 11 章)
pub mod skills; // 技能引擎的接线(第 7 章)
pub(crate) mod mcp; // MCP 接入(第 8 章)
mod mcp_skill_dependencies; // skill ↔ MCP 依赖:把第 7、8 章打通
mod exec; // 执行
mod exec_policy; // 执行策略:命令允不允许跑(第 9 章)
pub(crate) mod landlock; // Linux 沙箱(第 9 章)
pub mod windows_sandbox; // Windows 沙箱(第 9 章)
mod guardian; // 守护/复核(第 9 章)
mod connectors; // 连接器(第 8 章)
mod event_mapping; // 内部状态 → 对外事件(第 3、13 章)
pub use codex_prompts as review_prompts; // 评审提示词,重导出 codex-prompts crate(第 12 章)
mod thread_manager; // 线程/会话的总管
你看,把 core 这一个 crate 的模块树读一遍,几乎又把全书的层过了一遍。 这不是巧合——一个 agent 真正"跑起来"时,这些层是要在同一个进程里咬合协作的,所以它们在 core 里彼此为邻。
还有两个值得一提的细节,都是"纪律"的体现:
第一,lib.rs 文件头上有一行:
意思是:这个库里任何直接往 stdout/stderr 打印的代码,一律编译报错。 为什么这么狠?因为所有面向用户的输出都必须走专门的抽象(TUI 或 tracing 日志栈)——一个 agent 的输出要可被捕获、可被结构化、可被观测,绝不能有人随手 println! 一下就把信息漏到无人接管的地方。这一行,就是"可观测性"这条原则在源码最底层的强制。
第二,你会注意到 goals、memories、guardian、web-search、image-generation 这些,在 core 里有接线,但真正的实现被放进了 ext/ 目录下的独立 crate(ext/goal、ext/memories、ext/guardian……)。Codex 有一套扩展(extension)机制:把"可选的、可插拔的能力"从核心里剥出去。这又是"抵制往 core 加代码"的同一条纪律在起作用。
五、一条主数据流:一句话进来,发生了什么¶
地图画完了,最后我们快速走一遍"血液循环",让这些层动起来——细节留到后面各章,这里只求一个整体感。
你在命令行里敲下一句"把 utils/date.rs 里的时区 bug 修了",然后回车。大致会发生这样一串事(括号里是它落在哪一层 / 哪一章):
- 入口:
tui或exec把你这句话作为一次提交,交给core的会话总管thread_manager/session。(运行时 → 循环) - 拼上下文:
context/模块把这一轮要喂给模型的东西拼起来——系统提示、AGENTS.md里的规矩、当前目录与沙箱状态、相关历史。(上下文,第 4 章) - 调模型:
client.rs把拼好的上下文打成请求发给模型,流式收回它的回复。(循环 → 模型,第 3 章) - 模型要调工具:模型说"我要用
apply_patch改这个文件 / 我要先用 shell 跑个测试"。tools/的注册表 + 路由把这个调用分发到对应的 handler。(工具,第 5–6 章) - 过安全闸:真正执行前,
exec_policy判定这条命令允不允许跑,沙箱(landlock/windows_sandbox)把它关进只能动该动的地方,必要时guardian复核、或弹出审批问你。(约束·安全,第 9 章) - 执行并回灌:命令/补丁在沙箱里执行,结果(stdout、退出码、新的文件状态)被
event_mapping转成事件,喂回模型。(循环,第 3 章) - 循环:模型看到结果,决定下一步——继续改、跑测试验证、还是收工。如此往复,直到它认为做完。中途若上下文快满了,
compact*会把历史压一压;若这是个跨越好几个窗口的大活,goals/memories会留下"交接班"的工件。(循环 + 长程,第 3、10 章)
把这七步对回第一节那张同心层图:一次请求,就是从外层一路穿到内核(模型),再带着结果一路穿回外层的过程。每一层都在这条路径上拦一道、加一点。下一章,我们就把第 1、3、6 步——也就是最内圈的"循环"——掰开揉碎,从一个几百行的极简 agent(pi)讲到 Codex 的 session/turn.rs。
六、怎么读这套源码(不迷路指南)¶
最后给你几条本书一以贯之的读码方法,省得你重蹈"被一屏目录劝退"的覆辙:
- 别从头读到尾。 没人这么读大型代码库。永远从"我想搞懂哪一层"出发,照第三节那张总索引,只去那一层对应的几个文件。
- 先读
README.md。 几乎每个 crate 都有自己的README.md,是最好的入口;core/README.md还专门写了三平台沙箱的支持矩阵。 - 用
rg(ripgrep)顺着符号走。 想知道某个结构体/函数在哪被用,rg 名字比顺着目录翻快十倍。读源码是"跳着读",不是"线性读"。 - 只读三样东西:数据结构、控制流、边界。 一个模块,先看它定义了哪些 struct/enum(数据结构)、关键函数在什么时候被谁调用(控制流)、它在哪里拦截/校验/转换(边界)。Rust 的生命周期、宏、
async细节,一律先跳过——它们几乎不影响你理解 harness 的设计。完全不熟 Rust 也没关系:书里会碰到的记号,文末 附录:Rust 速查表 用 Python 类比一表列清,卡住时翻回去对一眼即可。 - 跟着本书的"四步法"走。 每章我们先抛一个失败场景,再讲机制,再带你读那几个关键文件,最后抽象成你能搬走的原则。你不需要自己在 116 个 crate 里探险——我们已经替你选好了每章该读的那几页。
本章小结¶
agent = model + harness,而 harness 可以拆成同心层:循环 → 上下文 → 工具 → 能力 → 约束安全 → 长程 → 多代理 → 评估观测 → 运行时。模型在最内核,是唯一你不掌控的部件。- Codex 是个 116 个 crate 的 workspace,crate 数量本身就是一种纪律——"抵制往
core加代码",用一道道 crate 边界和几十条 deny 级 lint 把架构焊死。好的 harness,往往先是好的架构。 - 代码地图几乎是概念地图的投影:每一层都能对到一两个名字直白的 crate;本书以"层"而非"crate"为单位推进,每章只读那一层关键的三五个文件。
- 读码四原则:从层出发、先读 README、用
rg跳读、只看数据结构/控制流/边界。
下一章,我们钻进最内圈——循环。先用 pi、Hermes 这两个极简 agent 看清"一个 agent loop 最少需要什么",再打开 Codex 的 session/turn.rs,看它为"生产级"在这个朴素内核上,到底多做了什么。
参考来源¶
解剖标本(codex-rs 源码)
Cargo.toml— 116 个 workspace 成员、clippy deny 列表core/src/lib.rs— core 模块树、#![deny(clippy::print_stdout)]core/README.md— 三平台沙箱支持矩阵AGENTS.md— "resist adding code to codex-core"
方法论
- OpenAI《Harness engineering》 — taste invariants、机械强制边界
- LangChain《The Anatomy of an Agent Harness》 — agent = model + harness
- LangChain《Agent Frameworks, Runtimes, and Harnesses, Oh My!》 — framework / runtime / harness 之分
注:crate 数量与具体名称以你 clone 的版本为准(Codex 在持续演进),写作定稿前用
rg/ls复核最新 workspace 成员列表即可。