第 3 章 Agent 循环:一次 turn 的生命周期¶
上一章我们画了地图。从这一章起,我们一层一层往里钻。最里面、紧贴着模型的那一圈,是循环(Loop)——它是把"模型会想"变成"agent 会做"的发动机。
本章的读法:先用两个极简 agent(pi 和 Hermes)看清"一个 agent loop 最少需要什么",再打开 Codex 的
session/turn.rs,看它为了"生产可用",在这个朴素内核上到底多加了什么、又是为了兜住哪些真实的坑。这套"从极简到生产"的对照,会是本书反复使用的手法。
引子:没有循环,模型只能"说一句话"¶
回想第 1 章那个让人泄气的画面:你让模型修个 bug,它给你一段代码,你运行、报错、贴回去、它再改……来回十几轮,全靠你这个人在中间当"传话筒"和"执行器"。
把这件事看穿了,你会发现:模型本身只会做一件事——给定一段输入,吐出一段输出。它不会自己去读文件、跑测试、看报错。让它"自己干活"的,是外面有一个循环,不停地:把上下文喂给模型 → 看它想调用什么工具 → 替它执行 → 把结果再喂回去 → 再问它下一步。直到它说"我做完了"。
这个循环,就是 agent 的发动机。 没有它,再强的模型也只是个聊天框。这一章,我们就来拆这台发动机——从最简陋的,到 Codex 那台带涡轮增压的。
一、最小的循环:四个工具加一个 while¶
要看清一台发动机的原理,最好的办法是先看最简单的那台。
2025 年底,Mario Zechner 写了一个叫 pi 的极简编码 agent。它简单到什么程度?四个工具(读文件、写文件、改文件、跑命令)、一个朴素的循环、约 1000 个 token 的系统提示,外加给每个能力配的一句话描述。就这些。
它的循环是经典的 ReAct 式。我们不写伪代码,直接看它真实的循环骨架(packages/agent/src/agent-loop.ts 的 runLoop,我这里只裁掉了事件流细节和并行/串行工具执行分支,但保留了上下文注入、LLM 调用边界、工具结果回灌这些关键动作):
while (true) { // 外层:等“后续 / 插话”消息
let hasMoreToolCalls = true;
while (hasMoreToolCalls || pendingMessages.length > 0) { // 内层:真正的 agent loop
if (pendingMessages.length > 0) { // 先把排队的“插话”消息并进上下文
for (const message of pendingMessages) {
currentContext.messages.push(message);
newMessages.push(message);
}
pendingMessages = [];
}
// 在 LLM 调用边界,把 currentContext.messages 转成 llmMessages,
// 再拼成 llmContext { systemPrompt, messages, tools }
const message = await streamAssistantResponse(currentContext, config, signal, emit, streamFn);
newMessages.push(message);
if (message.stopReason === "error" || message.stopReason === "aborted") return; // 出错/被中止
const toolCalls = message.content.filter((c) => c.type === "toolCall");
const toolResults = [];
hasMoreToolCalls = false;
if (toolCalls.length > 0) {
const executed = await executeToolCalls(currentContext, message, config, signal, emit);
toolResults.push(...executed.messages);
hasMoreToolCalls = !executed.terminate; // 还有工具要跑就继续转
for (const result of toolResults) { // 把工具结果回灌进上下文
currentContext.messages.push(result);
newMessages.push(result);
}
}
pendingMessages = (await config.getSteeringMessages?.()) || []; // 跑完一轮后,再看用户有没有中途插话
}
const followUpMessages = (await config.getFollowUpMessages?.()) || [];
if (followUpMessages.length > 0) { pendingMessages = followUpMessages; continue; } // 用户又说话 → 再来一轮
break; // 没有了 → 收工
}
你现在应该能更具体地看到,这个 loop 里真正流动的东西是什么:用户消息先并进 currentContext.messages,模型回复回来也先落进历史;如果模型发了 tool call,工具结果会再作为 toolResult 消息继续塞回同一个上下文。 下一次调模型时,streamAssistantResponse() 再把这份 AgentMessage[] 历史转换成 llmMessages,连同 systemPrompt 和 tools 一起拼成 llmContext 发给模型。也就是说,pi 的循环不是抽象地"喂回去",而是真有一份不断长大的消息历史在往前滚。
剥掉流式和工具执行的细节,核心就这么点逻辑——已经能让一个模型"自己"读代码、改代码、跑测试了。值得先记一笔:pi 这个"极简"实现,其实已经有了内外两层循环——内层把"调模型→跑工具→喂回"转起来,外层等你"插话/补话"。等下你会看到,Codex 的两层结构(regular.rs 外层 + run_turn 内层)跟它惊人地一致。
顺带一提,pi 还催生了更"重装"的变体——比如 can1357 的 oh-my-pi:在同一颗循环心脏外,叠上子 agent、LSP、调试器(DAP)接入、基于内容锚点的编辑等,把 pi 长成了一套完整的 coding 工作台。但变的依旧是外圈,那颗循环心脏没动。
而朝相反方向,社区里还有更极端的——Geoffrey Huntley 的 "Ralph Wiggum" 模式,整个 agent 就是一句 shell:
把同一个提示一遍遍喂进去,让它自己往前拱。粗暴,但能跑。
这两个例子想说明的,是 agent loop 那个不可再简的内核:
调模型 → 如果它要工具,就执行并把结果喂回去 → 重复,直到它只说话、不再要工具。
记住这句话。接下来你会看到,无论是 Hermes 还是 Codex,循环的心脏都是它;它们的不同,全在"为了在真实世界里靠谱"而往这个内核外面加的东西。
二、Hermes:把循环做成一个"参考架构"¶
pi 告诉我们内核可以多简单。但你真要拿它去干长活、接多个模型、跑在多个平台上,就会开始缺东西。下一站,我们看一个把循环"做出结构"的开源实现:Nous Research 的 Hermes Agent(第 1 章那个 90 天 14 万星的项目)。
Hermes 的核心循环,和 pi 是同一个心脏——用它自己的描述:模型调用 → 工具分发 → 把工具结果追加回去 → 重复,直到产出最终回复或被中断。它把这颗心脏单独拆进了 agent/conversation_loop.py,外面再环绕一圈各司其职的模块。换句话说,Hermes 的目录结构本身,就是一张"参考架构图":循环在最中间,周围是上下文、压缩、策展、预算、各家模型适配器——一层层把"裸循环"包成了能上生产的样子。
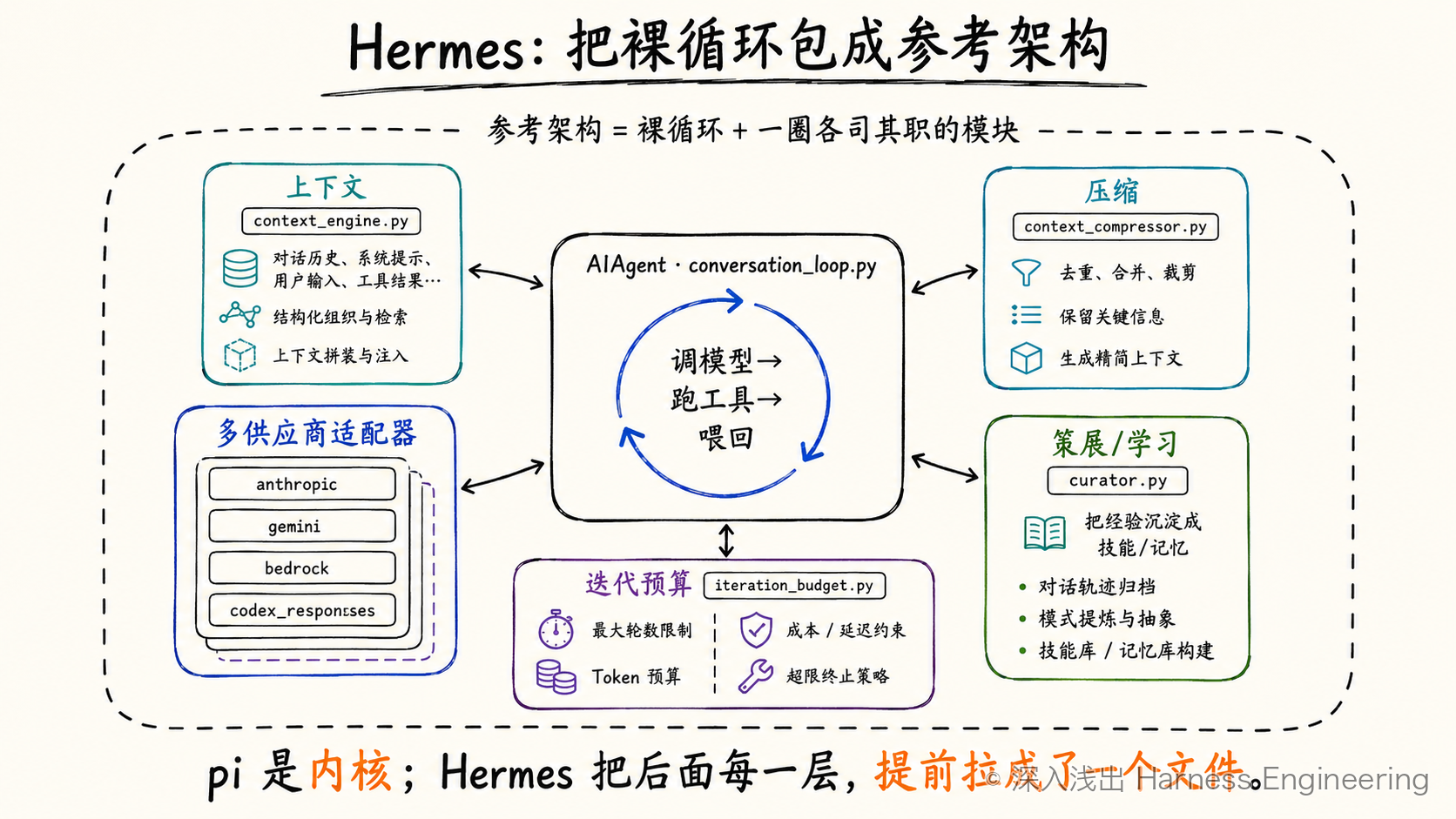
图 4:Hermes 把裸循环包进 AIAgent,周围再配上上下文、压缩、学习、预算和多模型适配模块。
它在心脏外面做的这几件"工程化"的事,值得记下来,因为 Codex 也会做同样的事,只是更彻底:
- 用一个类持有会话状态:整个会话的状态收进一个
AIAgent类(run_agent.py起家,现已拆到agent/下一票模块),而不是散在一堆全局变量里。一个 turn 跑起来,状态有明确的归属。 - 把"工具注册"和"工具暴露"分开:你可以注册一百个工具,但不等于每一轮都把这一百个的说明都塞进模型的上下文。这条,正是第 8、9 章"不撑爆上下文"的雏形。
- 抽象掉模型供应商:同一套循环,能驱动 OpenAI、Anthropic、Gemini、Bedrock、甚至 Codex 的 Responses 通道——证据就摆在目录里,
anthropic_adapter.py/bedrock_adapter.py/gemini_native_adapter.py/codex_responses_adapter.py一排适配器,把各家 API 的差异抹平成同一套接口。 - 把"会成长"也做成了模块:这是 Hermes 最出彩的地方(第 1 章说它"会跟你一起成长")。
context_engine.py+context_compressor.py管上下文的拼装与压缩、curator.py把经验"策展"成可复用的技能/记忆、iteration_budget.py给自主迭代上预算闸——这三件事,正好分别预告了本书第 4、5 章(上下文与压缩)、第 8 / 11 章(技能与长程记忆)、第 11 章(预算)。
如果说 pi 是"能跑的内核",Hermes 就是"有模有样的参考架构"——它已经把后面我们要逐章拆的那些层,提前拉出来各成一个文件了。而 Codex,是把同样这些事做到生产级、跨平台、可配置的那一版。我们这就进去。
三、进入 Codex:先把"输入"和"输出"解耦¶
打开 Codex 的核心,你会发现它在写循环之前,先做了一件 pi 和 Hermes 都没怎么强调的事:把"你给 agent 下指令"和"agent 给你吐进展"这两件事,拆成两条独立的队列。
一条是提交(submission)队列,承载 Op——你(或 UI、或另一个 agent)想让它做什么。打开 protocol/src/protocol.rs,Op 是个枚举,列着所有"能提交的操作"(下面是本章第一段 Rust——不熟 Rust 没关系,看中文注释就够,记号对照见文末附录速查表):
pub enum Op {
Interrupt, // 中断当前任务
UserInput { items, .. }, // 用户输入(开启一个新 turn)
ExecApproval { id, decision, .. }, // 批准/拒绝一条命令的执行
PatchApproval { id, decision }, // 批准/拒绝一个代码补丁
// …… 还有实时对话、线程设置、代理间通信等
}
另一条是事件(event)流,承载 Event / EventMsg——agent 想告诉你什么。同一个文件里,EventMsg 也是个大枚举:turn 开始了(TurnStarted)、模型又吐了一段字(AgentMessageContentDelta)、turn 完成了(TurnComplete)、turn 被中断了(TurnAborted)……
为什么要这么拆?因为这一拆,换来了三个对"生产可用"至关重要的能力:
- UI 不会被卡住:你提交一个
Op就立刻返回,agent 在后台慢慢跑,进展通过 event 流源源不断推回来——所以你能看到它一个字一个字地"打字"。 - 你能中途插话、能喊停:agent 跑着的时候,你随时能再提交一个
Op(继续补一句话,或者Interrupt喊停)。这就是"steering"(操舵)——人掌舵、agent 执行。 - 同一个核能被不同前端驱动:TUI、IDE、
codex exec、甚至另一个 agent,谁都只是"提交 Op、消费 Event",核心逻辑一份不用改。(这条我们留到第 15 章运行时再展开。)
记住这张图:你往里递 Op,它往外吐 Event,中间那台不停转的,就是循环。
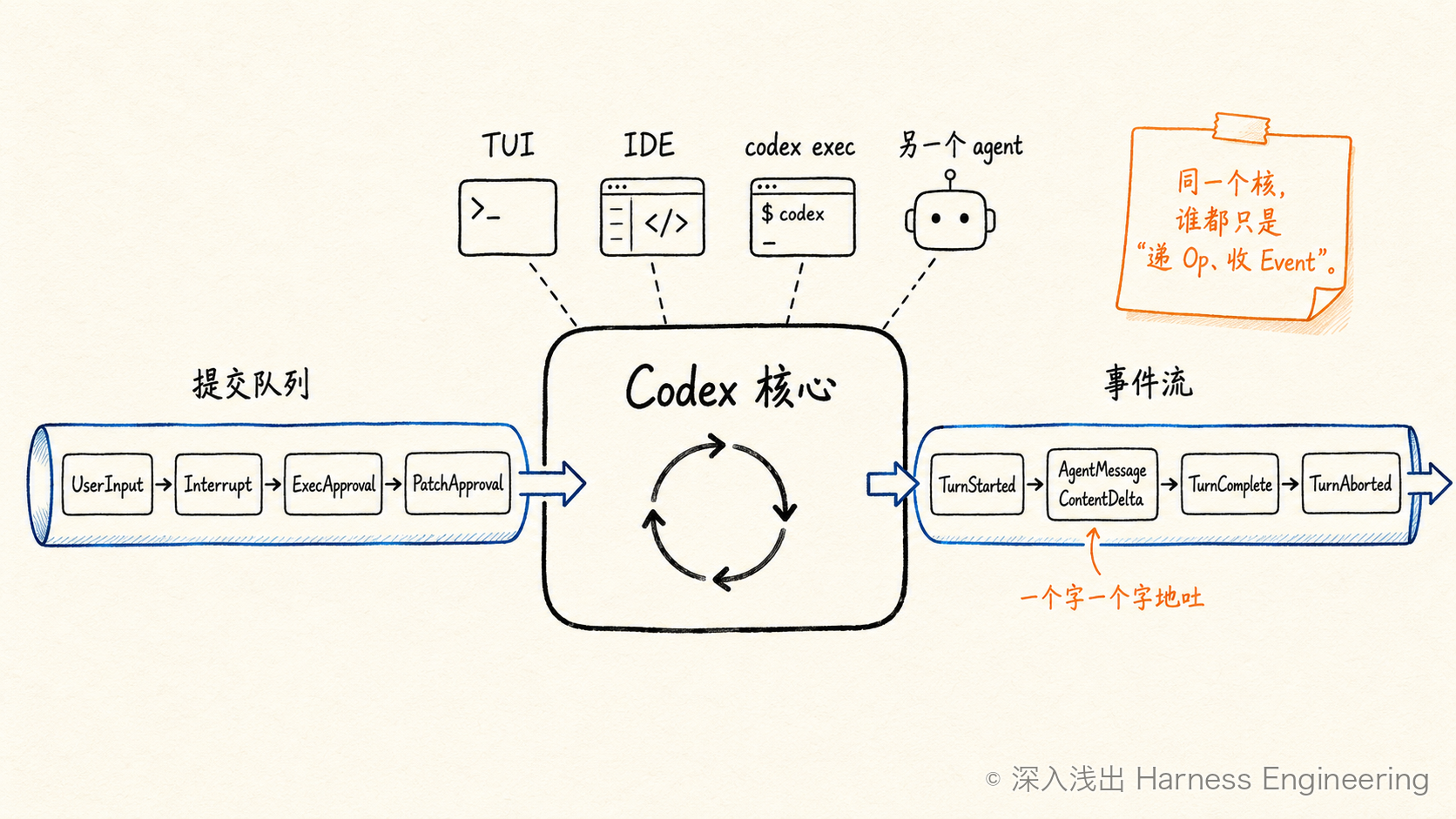
图 3:同一个 Codex 核接收 Op,持续吐出 Event,因此可以被不同前端复用。
四、一次 turn 的生命周期:它其实是一个"任务"¶
在 Codex 里,一个 turn 不是一段直接跑的函数,而是一个任务(task)。core/src/tasks/mod.rs 定义了一个很小的 trait:
pub(crate) trait SessionTask: Send + Sync + 'static {
fn kind(&self) -> TaskKind; // 我是哪种任务
fn span_name(&self) -> &'static str; // 给 tracing 用的名字
async fn run(self, session, ctx, input, cancellation_token) -> Option<String>; // 干活
async fn abort(&self, session, ctx) {} // 被取消时收尾(默认空)
}
为什么要包成"任务"?因为一个 turn 不只有"普通聊天"一种。Codex 里 SessionTask 有好几个实现:RegularTask(普通对话)、ReviewTask(代码评审,第 13 章)、CompactTask(压缩历史,第 5 章)、UserShellCommandTask(你直接敲的 shell)。它们的工具集、系统提示其实都一样,区别只在"这一轮带着什么使命开场"——这也正是 Anthropic 那篇长程 agent 文章里"initializer agent / coding agent 只是初始提示不同"的同一个思路。
任务的生命周期由 Session 管。当一个新 turn 进来,spawn_task 会先做一件很重要的事——把上一个还在跑的任务中止掉:
pub async fn spawn_task<T: SessionTask>(self, turn_context, input, task) {
self.abort_all_tasks(TurnAbortReason::Replaced).await; // 同一时刻只允许一个活跃 turn
self.clear_connector_selection().await;
self.start_task(turn_context, input, task).await;
}
start_task 接着把任务丢到一个后台 Tokio 任务上去跑,并给它开一个 tracing span——这个 span 上挂着一堆字段:输入/输出/缓存/推理 token 数。从循环的第一行起,这一轮烧了多少 token 就在被记账了(这个 span 名叫 session_task.turn,第 14 章可观测性会回到它)。任务跑完,on_task_finished 统一发出一个 EventMsg::TurnComplete,带上耗时、首字延迟(TTFT)等。
所以一次 turn 的外壳,就是下面这张图:
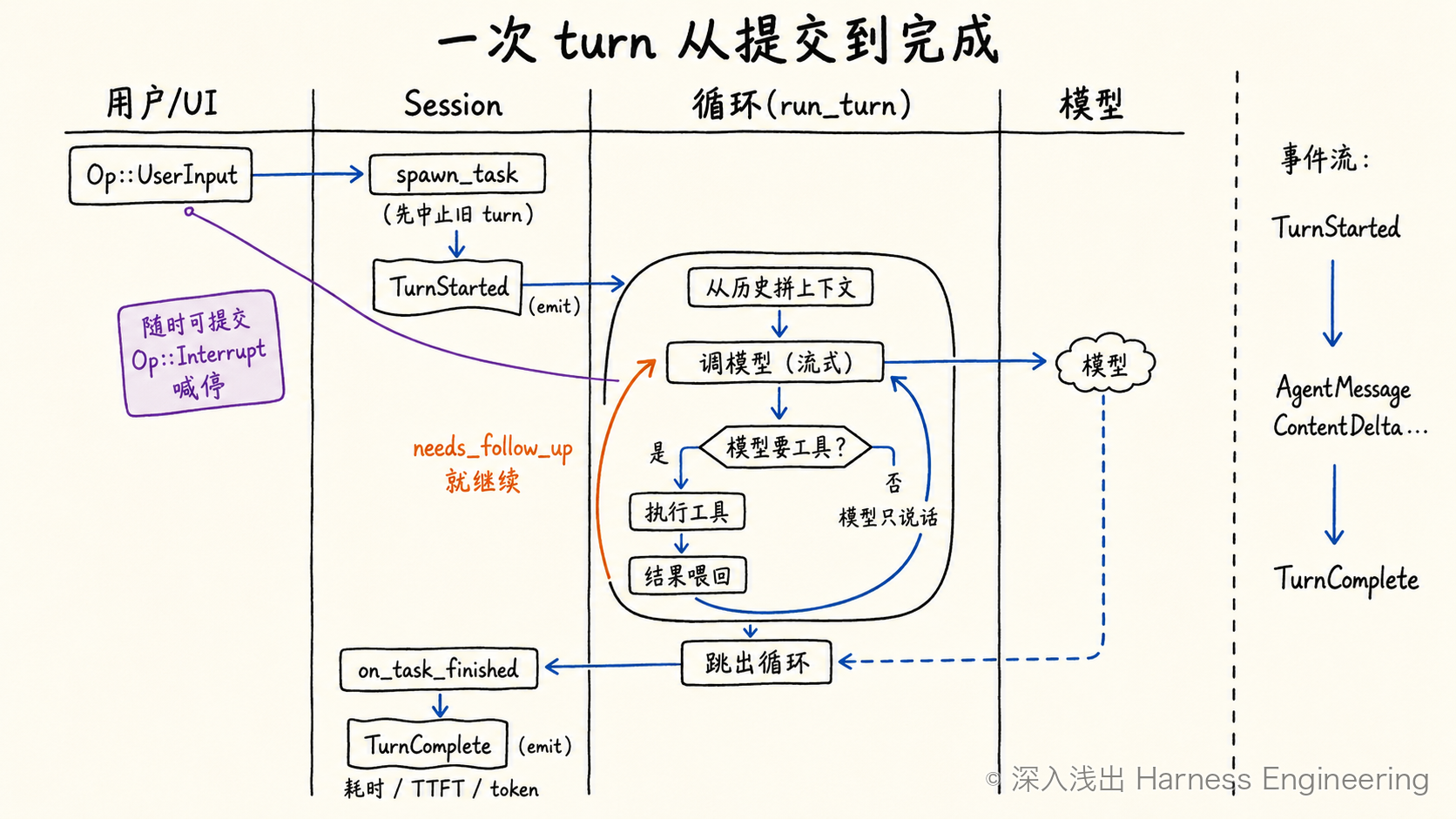
图 2:一次 turn 从 Op::UserInput 提交,到 TurnComplete 收尾,中间由 run_turn 循环驱动。
五、循环的心脏:run_turn¶
终于到发动机本身了。普通对话任务 RegularTask 干的活,是套了两层循环。
外层循环很短,在 tasks/regular.rs 里,它处理的是"用户中途插话":
loop {
let last_agent_message = run_turn(/* …, */ next_input, /* … */).await;
// 跑完一轮后,如果用户趁它干活时又输入了东西,就再跑一轮把这些消化掉
if !sess.input_queue.has_pending_input(&sess.active_turn).await {
return last_agent_message; // 没有待处理输入了,真正收工
}
next_input = Vec::new();
}
内层循环才是真正的 agent loop,在 session/turn.rs 的 run_turn 里。这个函数头上的文档注释,几乎是对"agent 循环"最干净的一句定义,原文大意:
在每次采样请求时,模型要么回来一组函数调用,要么回来一条助手消息。如果是函数调用,我们就执行它、把输出在下一次采样请求里送回模型;如果只是一条助手消息,我们就把它记进对话历史,认为这一轮结束。
把它落成代码,run_turn 的循环骨架是这样(大幅简化)。别逐字抠 Rust 语法——跟着注释里标的 1)~4) 四步看流程就行:
loop {
// 1) 从“历史”拼出这一轮要发给模型的输入(上下文工程,第 4 章)
let sampling_request_input = sess.clone_history().await.for_prompt(/* … */);
// 2) 调模型:流式收回它的回复,并就地分发/执行它要的工具(第 6 章详解)
match run_sampling_request(/* …, */ sampling_request_input, /* … */).await {
Ok(out) => {
// needs_follow_up = 模型还要继续(调了工具)或 用户又插了话
let needs_follow_up = out.needs_follow_up
|| sess.input_queue.has_pending_input(&sess.active_turn).await;
// 3) 上下文要满了?先压缩,再继续(第 5 章)
if token_limit_reached && needs_follow_up {
run_auto_compact(/* … */).await?;
continue;
}
// 4) 模型只说了话、没要工具、也没人插话 → 本轮结束
if !needs_follow_up {
last_agent_message = out.last_agent_message;
break;
}
continue; // 否则:带着工具结果,进入下一次采样
}
Err(CodexErr::TurnAborted) => break, // 被中断(见下一节)
Err(e) => { /* 发 Error 事件,结束本轮,但让会话能继续 */ break; }
}
}
last_agent_message
请把这段和第一节 pi 的真实循环并排看——不只心脏相同,连"内层跑工具、外层等插话"的两层结构都一样:调模型 → 要工具就执行、needs_follow_up 为真、继续 → 只说话就 break。Codex 没有发明新的循环,它只是在这颗心脏周围,接上了生产环境需要的管线:
- 第 1 步的"从历史拼输入"——意味着上下文不是凭空给的,而是从会话历史里按规则组装的(整个第 4 章在讲这件事)。
- 第 2 步的
run_sampling_request——把"流式接收模型输出 + 把它要的工具调用分发出去执行"封进了一个函数(第 6 章我们会钻进去)。 - 第 3 步那个
if token_limit_reached——压缩被直接焊进了主循环:一轮跑下来发现上下文要爆了,就地压一压再继续。这就是长程 agent 能连续干几个小时的关键之一(第 5 章)。 Err(e)那一支也有讲究:出错时它发个Error事件、结束本轮,但不杀死会话——你还能接着跟它说话。生产级的循环,错误处理往往比"happy path"还多。
六、中断与"换班的礼貌":Op::Interrupt¶
pi 那个 while 循环有个隐藏的残忍之处:你按 Ctrl-C,它可能正写到文件一半。生产级 agent 必须能优雅地被打断。
在 Codex 里,你喊停就是提交一个 Op::Interrupt。它最终走到 handle_task_abort,做的事很能体现"工程 vs 玩具"的差别:
task.cancellation_token.cancel(); // 先礼:通知任务“该收手了”
select! {
_ = task.done.notified() => { } // 任务自己优雅停下了
_ = sleep(Duration::from_millis(100)) => { // 只给 100ms 宽限
warn!("task didn't complete gracefully …");
}
}
task.handle.abort(); // 后兵:超时就硬砍
先发一个取消信号(CancellationToken,而且是一路 child_token() 传下去的,所以能层层传播到正在执行的工具),给任务 100 毫秒"把手头的事放下"的时间;过期不候,硬中止。最后发出 EventMsg::TurnAborted 告诉你停了。
但真正精彩的是这一笔:中断时,Codex 会往对话历史里写一条"这一轮是被中断的"的标记(interrupted_turn_history_marker,以 developer/contextual 角色注入)。为什么?因为下一轮的模型需要知道上一轮没干完——不然它会以为上一轮顺利结束,接着往下走,把烂摊子越铺越大。
这一条小小的"换班标记",是整本书的一个缩影:harness 工程的本质,就是把人类协作里那些不言自明的礼貌("我这摊还没弄完就被叫走了,得跟接班的交代一声"),翻译成 agent 能在上下文里读到的工件。 这个主题,到第 11 章(跨窗口"换班")会被放到最大。
七、从极简到生产:Codex 在朴素内核上加了什么¶
把这一章收束一下。同一个循环心脏,三个版本:
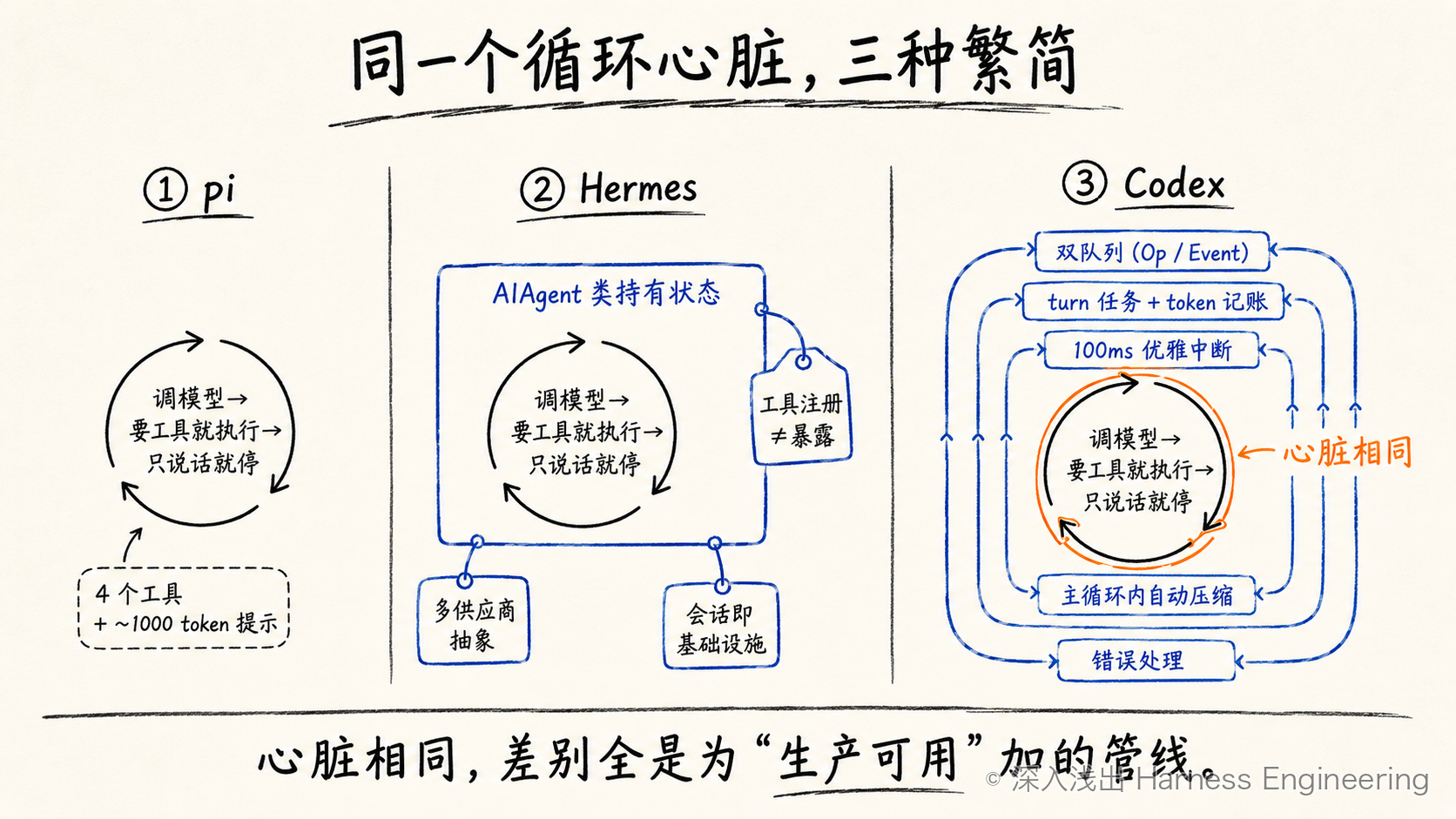
图 1:三者的循环心脏相同,差异主要来自生产可用性所需的外围工程管线。
| 心脏(调模型→要工具就执行→只说话就停) | 外面加了什么 | |
|---|---|---|
| pi | ✓ | 四个工具 + ~1000 token 提示,够极简 |
| Hermes | ✓ | 会话状态收进一个类、工具注册与暴露分离、多供应商抽象 |
| Codex | ✓ | Op/Event 双队列解耦、turn 作为可中止的后台任务、token 记账与 tracing span、100ms 优雅中断 + 中断标记、主循环内自动压缩、丰富的错误处理与 hook |
看这张表的正确姿势,不是"Codex 好复杂",而是:Codex 多出来的每一样,都对应一个 pi 在真实世界里会栽的跟头——UI 卡死、没法喊停、喊停了下一轮还接着犯错、跑长了上下文爆掉、一个网络错误就把整个会话搞崩。所谓"生产级",就是把这些跟头一个个用工程兜住。
这也立下了本书后面每一章的基调:我们不会因为 Codex 的某段代码复杂就膜拜它,而是始终去问那句——"它在解决哪个真实的失败?" 把那个失败想清楚了,复杂就变成了"原来如此"。
本章小结¶
- 循环是 agent 的发动机:模型只会"给输入吐输出",是外面的循环让它能读、能改、能验证、能多步地干活。
- 循环的不可再简内核:调模型 → 它要工具就执行并把结果喂回 → 重复,直到它只说话、不再要工具。pi、Hermes、Codex 的心脏都是这一个。
- Codex 的工程化:先用
Op/Event双队列把输入输出解耦(换来不卡 UI、可中途操舵、可被多前端驱动);把一个 turn 包成可中止的后台任务(带 token 记账与 tracing span);run_turn的内层循环就是那颗心脏,外层再包一层"用户插话就续跑"。 - 生产级体现在边角:100ms 优雅中断 + 一路传播的取消信号、给下一轮留"被中断"标记、主循环内自动压缩、出错不杀会话。每一样都对应一个真实的坑。
下一章,我们顺着 run_turn 第一步那句 clone_history().for_prompt(...) 往里走——看 Codex 到底把什么、按什么顺序,拼进每一轮喂给模型的上下文。那是 harness 里最稀缺、最该精打细算的资源。
延伸:从 one shot 到 loop engineering¶
把镜头再往外拉一格。本章这颗循环,对外其实是"一发"——你给一个任务,它自己跑一趟到收尾(one shot)。2026 年热起来的 loop engineering(循环工程),就是把这"一发"变成"自己反复跑":在 agent 外面再套一层,让系统按计划或 cron 不断发现任务、派子代理、验证结果、把状态落盘、决定下一步,直到目标达成——"趁你睡觉它自己跑"。
放进这几年的进化阶梯就清楚了:prompt engineering → context engineering(第 4 章)→ harness engineering(本书主线)→ loop engineering。区分只有一句:harness 给单次运行配齐装备(工具、上下文、权限、护栏);loop 在其上做自动驾驶。它和"裸写个 while True 反复喊模型"的差别也在护栏——Anthropic 把 agent 朴素地描述成"在循环里、根据环境反馈使用工具的 LLM",loop engineering 不过是把那个"循环"本身当成了工程对象;而没有验证与状态约束的循环,只会更快地跑偏(本章末尾引的 Ralph Wiggum,就是这种"把 agent 塞进循环反复跑"的早期土法)。
本章先把"循环"这颗种子种下;把它工程化所需的零件,其实散在后面——长程的目标与记忆(第 11 章)、多代理的派生与换班(第 12 章)、自我验证(第 13 章)、headless 入口(第 15 章),到第 16 章收口成"造你自己的 harness"。
参考来源¶
解剖标本(codex-rs 源码)
core/src/session/turn.rs—run_turn主循环core/src/tasks/mod.rs—SessionTask、任务生命周期与 100ms 优雅中断core/src/tasks/regular.rs—RegularTask插话续跑protocol/src/protocol.rs—Op/Event/EventMsg
极简 agent 参照
- pi(Mario Zechner)(循环在
packages/agent/src/agent-loop.ts) - oh-my-pi(can1357,pi 的重装变体:子 agent / LSP / 调试器 / 锚点编辑)
- Ralph Wiggum(Geoffrey Huntley)
- Hermes Agent(Nous Research)
方法论
- Anthropic《Building effective agents》(agent = "在循环里、根据环境反馈使用工具的 LLM" 的一手定义,loop engineering 常以此为出发点)
- Anthropic《Effective harnesses for long-running agents》
- Inngest《Your Agent Needs a Harness, Not a Framework》
注:
run_turn实际还含自动压缩、stop hook、图片消毒等分支,本章为讲主干做了简化;符号以你 clone 的版本为准。